Toma de decisiones clínicas basadas en pruebas científicas
EVIDENCIAS EN PEDIATRÍA

Septiembre 2024. Volumen 20. Número 3
| Herramientas para cálculo de tamaño muestral
Valoración: 0 (0 Votos)Autores: Albi Rodríguez MS, Ortega Páez E.
 Suscripción gratuita al boletín de novedades
Suscripción gratuita al boletín de novedades
Reciba periódicamente por correo electrónico los últimos artículos publicados
Suscribirse |
Autores:
Correspondencia:
Introducción
Para evaluar correctamente un ensayo clínico, en ocasiones no disponemos de la información completa sobre la forma de establecer el tamaño muestral necesario para el estudio, lo que nos puede llevar a conclusiones inadecuadas.
En los últimos años se han desarrollado múltiples herramientas para el cálculo del tamaño muestral mediante programas, calculadoras o aplicaciones en línea o descargables, algunos de acceso libre y otros no gratuitos.
Cálculo del tamaño muestral
El tamaño de la muestra puede calcularse para casos de predicción sobre comparación de medias y proporciones, y para casos de contraste de hipótesis:
Cálculo de tamaños de muestra en casos de predicción:
- Estimación de una media (variables cuantitativas).
- Estimación de una proporción (variables cualitativas).
Cálculo de tamaños de muestra en casos de contraste de hipótesis:
- Comparación de 2 proporciones.
- Comparación de 2 medias.
- Estimaciones del riesgo relativo (RR) y odds ratio (OR).
En función de la medida de resultado, para estimar correctamente el tamaño muestral necesario, debemos considerar la diferencia clínicamente importante y los errores tipo I y II. Habitualmente, el error tipo I suele establecerse en el 5% y el II, en el 20%.
La precisión o diferencia a estimar la suele establecer el investigador dependiendo de si hay estimaciones de referencia previas con las que comparar, la estimación de la diferencia clínicamente importante y la factibilidad para reclutar sujetos para la muestra.
Deberemos establecer también la proporción esperada. Podemos recurrir a nuestro conocimiento previo sobre el objeto de estudio o buscar datos en la literatura publicada. Cuando no tenemos ninguna idea previa de la frecuencia esperada, la estrategia más conservadora es realizar el cálculo asumiendo que la prevalencia esperada es del 50% (0,50).
Herramientas para el cálculo del tamaño muestral
Los programas utilizan diferentes algoritmos matemáticos para efectuar el cálculo y, aunque utilizan los mismos elementos, puede haber ligeras diferencias en el número de la muestra. Entre los programas más utilizados están EPIDAT®, GranMo, G*Power® y Epi Info® de acceso libre. Las hojas de cálculo como Excel son también de utilidad. Entre los software gratuitos destaca R Software, y entre los no gratuitos, Stata®, SAS®, STATISTICA® y SigmaPlot®, por mencionar algunos. Los dos últimos tienen la ventaja de que permiten hacer gráficas de las funciones de estimaciones del tamaño de la muestra (Tabla 1).
Tabla 1. Herramientas calculadoras del tamaño muestral. Mostrar/ocultar
EPIDAT
Es un programa informático que pertenece a la Xunta de Galicia. Desde 2016 existe una versión EPIDAT 4.2 en inglés, portugués y castellano, que aporta ciertas ventajas con respecto a versiones anteriores. La ruta de acceso es la siguiente: www.sergas.gal/Saude-publica/EPIDAT-4-2
EPIDAT 4.2 no requiere instalación, solo es necesario descargar y descomprimir el programa en una carpeta del disco duro que tenga permisos de escritura. El programa se ejecuta por medio del archivo Epidat.jar. Puede usarse en distintos sistemas operativos, tales como Windows, Linux u OS X. Para funcionar correctamente, EPIDAT 4 requiere Java 6.0 Update 18 o superior (www.java.com/es/download/). La ayuda (en formato PDF) y los archivos (en formato Excel) empleados para realizar los ejemplos de la ayuda están disponibles en la carpeta que se descarga con el programa.
Para descargar el programa es necesario cumplimentar un pequeño formulario.
Uno de los 18 módulos del programa es la herramienta de muestreo (Módulo 3) (Figura 1).
Figura 1. Herramienta de muestreo (Módulo 3). Mostrar/ocultar
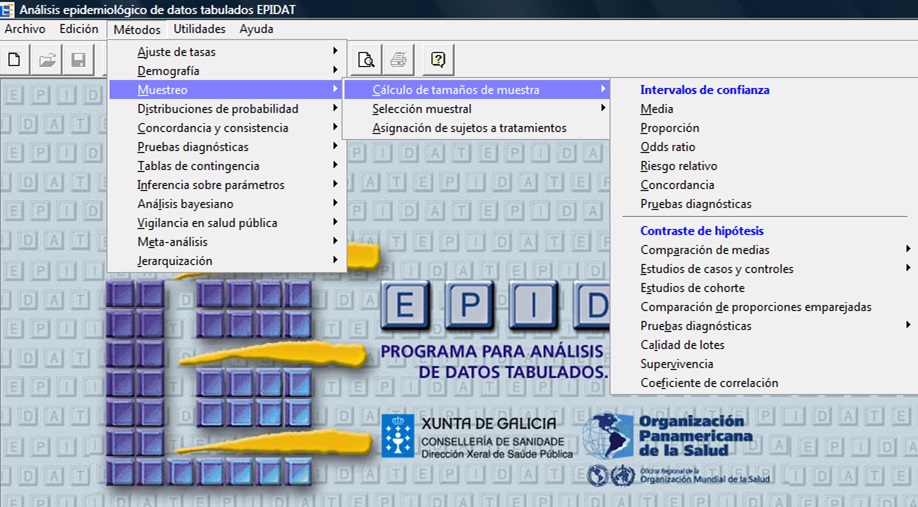
A continuación, desarrollaremos los cálculos que nos permite esta herramienta y la información que necesitamos cumplimentar en diferentes supuestos: (Figuras 2a, 2b, 2c y 2d).
Figura 2. EPIDAT. Herramienta de muestreo (Módulo 3). Ejemplos de cálculos para estimar tamaño muestral para: (a) media poblacional; (b) comparación de proporciones emparejadas; (c) medias independientes; (d) estudios caso-control/estimaciones de odds ratio. Mostrar/ocultar

1. El cálculo del tamaño muestral para los casos de predicción:
- Estimación de una media (variables cuantitativas): introducimos los datos de tamaño poblacional existente; la desviación estándar se obtiene de un estudio piloto, analizando los primeros datos y obteniendo una media y desviación estándar; o podemos extraerla de la bibliografía consultada. La precisión depende de los valores estudiados y el valor lo elige el investigador.
- Estimación de una proporción (variables cualitativas): igual que en ejemplo previo, introducimos los datos de tamaño poblacional existente; la desviación estándar se puede obtener de un estudio piloto o de la bibliografía consultada. La precisión tendrá un valor máximo de 5%. Aquí podemos poner un mínimo de 1% y un máximo de 5%. Hay que tener en cuenta que para que la diferencia sea más pequeña, mayor tamaño muestral necesitaremos. El nivel de confianza debe ser del 95% por lo menos.
2. El cálculo de los tamaños de la muestra en los casos de contraste de hipótesis:
- Comparación de dos proporciones: la proporción 1 y 2 serán proporciones obtenidas según bibliografía y/o prueba piloto. La precisión será siempre un máximo de 5%, y el nivel de confianza debe ser del 95%.
- Comparación de dos medias: en este cuadro es necesario conocer las desviaciones estándar en ambas poblaciones (A y B). Se pueden obtener de la bibliografía o de una prueba piloto. La diferencia de medias/razón entre muestras (B/A) será la que exprese la diferencia de tamaño de las muestras; generalmente, la razón entre muestras es de 1, para que los grupos sean del mismo tamaño. La precisión será siempre un máximo de 5%, y el nivel de confianza debe ser del 95%.
- Estimaciones del RR y OR: necesitamos conocer la proporción de casos expuestos/controles obtenidos por la bibliografía o por un estudio piloto. Los controles por caso: si ponemos 1, nos referimos a que los grupos serán del mismo tamaño (1 caso y 1 control). Si ponemos 2, habrá 2 controles por cada caso (1 caso y 2 controles). La precisión será siempre un máximo del 5%, y el nivel de confianza debe ser del 95%.
En cualquiera de los casos tendremos que seleccionar si se trata de un cálculo de predicción (muestra poblacional) o de contraste de hipótesis, y establecer el nivel de confianza y la precisión que queremos.
G*Power
Es un programa estadístico en inglés, de descarga gratuita, desarrollado por la Universidad de Dusseldorf y diseñado para realizar estimaciones de la potencia estadística y del tamaño del efecto. La última versión 3.1.9.7 (2020) puede ser descargada en: www.gpower.hhu.de
Está disponible para Windows e IOS. Realiza los tradicionales análisis a priori y post hoc en diseños ya terminados. El programa permite diversos cálculos, tales como el tamaño del efecto, la potencia esperada de un test, la muestra necesaria para lograr una determinada potencia; permite, además, verificar la significación respecto de las posibilidades reales del estudio, muestra resultados en diferentes ventanas, obteniéndose gráficas y tablas.
G*Power ofrece cinco tipos diferentes de análisis estadístico:
- A priori: el tamaño de la muestra N se calcula en función del nivel de potencia 1 − β, el nivel de significación α y el tamaño del efecto poblacional a detectar.
- Compromiso: tanto α como 1 − β se calculan como funciones del tamaño del efecto, N, y una razón de probabilidad de error q = β/α.
- Criterio: α y el criterio de decisión asociado se calculan en función de 1 − β, el tamaño del efecto y N.
- Post hoc: 1 − β se calcula en función de α, el tamaño del efecto poblacional y N.
- Sensibilidad: el tamaño del efecto poblacional se calcula en función de α, 1 − β y N.
El manejo del programa para realizar un análisis de potencia usando G*Power implica los siguientes tres pasos:
- Seleccione la prueba estadística apropiada para su problema.
- Elija uno de los cinco tipos de análisis de potencia disponibles.
- Proporcione los parámetros de entrada necesarios para el análisis y haga clic en "Calcular".
Epi Info / StatCalc
Dispone de un apartado que permite cálculos estadísticos, StatCalc. Una de las calculadoras permite el cálculo de tamaño muestral y potencia, incluyendo encuestas poblacionales, estudios cohorte, transversales y ensayos clínicos aleatorizados, así como estudios caso-control no pareados, proporciones y diferencia de medias. Los cálculos se pueden hacer también a través de la aplicación móvil, aunque esta solo permite cálculos para estudios poblacionales, y permite ajustar la frecuencia esperada (%) y los límites de confianza, proporcionando el tamaño muestral (N) para diferentes niveles de confianza (Figura 3).
Figura 3. Aplicación móvil Stat Calc. Mostrar/ocultar

GRANMO
Es una calculadora online, que disponía de un software descargable, desarrollada en el marco de un programa de investigación del Hospital del Mar (últimas versiones v7.12/ 2012; v8). A fecha de 13 de septiembre de 2024 sigue disponible el acceso online con varias interfaces:
https://laalamedilla.org/Investigacion/Recursos/granmo.html
https://www.datarus.eu/aplicaciones/granmo/
Permite el cálculo muestral con el uso.
Proporciones:
- Dos proporciones independientes.
- Observada respecto a una de referencia.
- Medidas apareadas (repetidas en un grupo).
- Bioequivalencia.
- Estimación poblacional.
- Odds ratio (estudios de casos-control)
- Riesgo relativo (estudios cohorte).
- Potencia de un contraste.
- Dos proporciones independientes por conglomerado (v8).
Medias. Diferencias entre:
- Dos medias independientes.
- Medias apareadas (repetidas en un grupo).
- Observada respecto a una de referencia.
- Medias apareadas (repetidas en dos grupos).
- Estimación poblacional.
- Análisis de la varianza.
- Potencia de un contraste.
- Dos medias independientes por conglomerado (v8).
Otras:
- Análisis de la supervivencia (prueba de log-rank).
- Coeficiente de correlación (v8).
- Coeficiente de correlación intraclase.
Veamos un ejemplo (Supuesto 1) v7.12:
En un estudio sobre la eficacia del bromuro de tiotropio en niños con episodios de sibilancias recurrentes, establecen como medida de resultado el número de días sin síntomas respiratorios (Kotaniemi-Syrjänen A et al., 2022).
Para el cálculo del tamaño muestral: plantean un poder del 80% para detectar una diferencia del 15% (1 día por semana) en el porcentaje de días libre de síntomas entre los grupos; asumen a través de datos de un estudio previo una desviación estándar (DE) del 27%; estiman una posible pérdida del seguimiento del 20% y establecen un nivel de significación para rechazar la hipótesis nula del 5%.
Seleccionamos la opción “diferencia de medias”. Introducimos la información en GranMo en cada apartado correspondiente. Si aceptamos un riesgo α de 0,05 y β de 0,2 (potencia 80%) y una proporción prevista de pérdidas del 20% (Figura 4), obtenemos el resultado:
Se calculó un tamaño muestral de 64 pacientes por grupo para encontrar diferencias de un 15% (correspondiente a un día por semana).
Figura 4. GranMo. Cálculo de tamaño muestral para medias independientes (Supuesto 1). Mostrar/ocultar

Bibliografía
- Epidat: programa para análisis epidemiológico de datos. Versión 4.2, julio 2016. En: SERGAS [en línea] [consultado el 13/09/2024]. Disponible en www.sergas.es/Saude-publica/EPIDAT?idioma=es
- Faul F, Erdfelder E, Lang AG, Buchner A. G*Power 3: a flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav Res Methods. 2007;39(2):175-91.
- Faul F, Erdfelder E, Buchner A, Lang AG. Statistical power analyses using G*Power 3.1: Tests for correlation and regression analyses. Behav Res Methods. 2009;41(4):1149-60.
- G*Power 3.1 manual June, 2023 [en línea] [consultado el 13/09/2024]. Disponible en psychologie.hhu.de/fileadmin/redaktion/Fakultaeten/Mathematisch-Naturwissenschaftliche_Fakultaet/Psychologie/AAP/gpower/GPowerManual.pdf
- García García JA, Reding Bernal A, López Alvarenga JC. Cálculo del tamaño de la muestra en investigación en educación médica. Invest Educ Med. 2013;2(8):217-24.
- Kotaniemi Syrjänen A, Klemola T, Koponen P, Jauhola O, Aito H, Malmström K, et al. Intermittent Tiotropium Bromide for Episodic Wheezing: A Randomized Trial. Pediatrics. 2022;150(3):e2021055860.
- Ochoa Sangrador C, Molina Arias M, Ortega Páez E. Inferencia estadística: estimación del tamaño muestral. Evid Pediatr. 2020;16:24.
Cómo citar este artículo
Albi Rodríguez MS, Ortega Páez E. Herramientas para cálculo de tamaño muestral. Evid Pediatr. 2024;20:39.
Envío de comentarios a los autores