Toma de decisiones clínicas basadas en pruebas científicas
EVIDENCIAS EN PEDIATRÍA

Septiembre 2016. Volumen 12. Número 3
| Evaluación de la validez de las pruebas diagnósticas (II). Valores predictivos
Valoración: 0 (0 Votos)Autores: Molina Arias M, Ochoa Sangrador C.
 Suscripción gratuita al boletín de novedades
Suscripción gratuita al boletín de novedades
Reciba periódicamente por correo electrónico los últimos artículos publicados
Suscribirse |
Autores:
Correspondencia:
En una publicación anterior1 desarrollamos los conceptos de sensibilidad y especificidad. La sensibilidad es la probabilidad de clasificar correctamente a los enfermos o, lo que es lo mismo, la proporción de verdaderos positivos. Por su parte, la especificidad es la probabilidad de clasificar correctamente a los sanos o, lo que es lo mismo, la proporción de verdaderos negativos2. Ambos indicadores nos dan información, antes de saber los resultados de una prueba, sobre su esperada validez.
El problema, como ya vimos entonces, es que cuando nosotros realizamos una prueba diagnóstica a un paciente queremos saber la probabilidad de que el paciente esté enfermo en función del resultado de la prueba, una vez conocido este. Sin embargo, la sensibilidad nos da la probabilidad de que la prueba sea positiva una vez que sabemos que el paciente está enfermo, mientras que la especificidad nos da la probabilidad de que el paciente tenga un resultado negativo una vez conocido que está sano. Por lo tanto, aunque ambos parámetros miden la capacidad de la prueba diagnóstica para discriminar entre sanos y enfermos (cuando ya sabemos si lo están), no modifican nuestra posición entre los umbrales diagnóstico y terapéutico3.
La pregunta es: ¿tenemos forma de saber la probabilidad de que el paciente esté enfermo una vez que la prueba sea positiva, o sano una vez que sea negativa? Esto es lo que buscamos en nuestra práctica diaria y una forma de saberlo es calculando los llamados valores predictivos4.
Recordemos el ejemplo del artículo anterior de 100 pacientes con síndrome miccional a los que realizamos tira reactiva y urocultivo (patrón de referencia) según se describe en la tabla 1.
Tabla 1. Ejemplo de realización de tira reactiva y urocultivo (patrón de referencia) en una población de niños con síndrome miccional Mostrar/ocultar
Definamos en primer lugar el valor predictivo positivo (VPP) como la probabilidad de estar enfermo una vez que el resultado es positivo. En el denominador pondremos el total de positivos, mientras que en el numerador pondremos aquellos enfermos que dan positivo a la prueba. En nuestro caso es de 26 / 42 = 0,61 (o 61%).
Por su parte, el valor predictivo negativo (VPN) será la probabilidad de que un negativo esté sano. En el denominador pondremos el número total de negativos y en el numerador en número de sanos que tienen prueba con resultado negativo. En el ejemplo vale 54 / 58 = 0,93 (o 93%).
En la figura 1 tenemos esquematizados los valores predictivos positivo y negativo.
Figura 1. Esquema de los valores predictivos positivo y negativo. Mostrar/ocultar
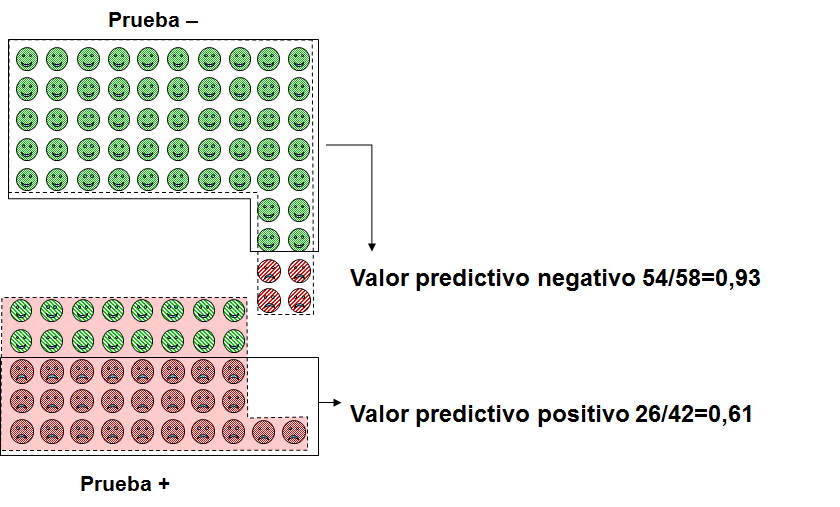
Bien, ya tenemos dos parámetros que nos informan acerca del valor de la probabilidad posprueba, que es lo que buscamos desde el comienzo. ¿Cuál es el problema? Que los valores predictivos, tanto el positivo como el negativo, dependen de la prevalencia de la enfermedad o, lo que es lo mismo, de la probabilidad preprueba.
Si lo pensamos detenidamente tiene su lógica. Si la enfermedad es muy frecuente, la probabilidad de que el positivo sea verdadero será mayor. Aunque sea por azar, será más probable que un positivo esté enfermo que cuando la enfermedad es más rara.
Por otra parte, si la enfermedad es muy rara existirá una mayor probabilidad de que el negativo esté sano, aunque sea solo por azar.
Veamos que esto se cumple con un ejemplo práctico. Supongamos que realizo una prueba diagnóstica a 1598 pacientes de una consulta hospitalaria y obtengo los resultados mostrados en la tabla 2. Podemos calcular los valores de sensibilidad, especificidad, VPP y VPN de la siguiente forma:
- Sensibilidad = 428 / 520 = 0,82.
- Especificidad = 1060 / 1078 = 0,98.
- VPP = 428 / 446 = 0,96.
- VPN = 1060 / 1152 = 0,92.
- Prevalencia = 520 / 1598 = 0,32.
Tabla 2. Ejemplo de prueba diagnóstica realizada en población hospitalaria. Mostrar/ocultar
Ahora vamos a suponer que realizo la misma prueba diagnóstica y en las mismas condiciones en una población tomada de un Centro de Salud y obtengo los datos mostrados en la tabla 3. Si repetimos el proceso obtenemos los siguientes valores:
- Sensibilidad = 100 / 122 = 0,82.
- Especificidad = 1000 / 1020 = 0,98.
- VPP = 100 / 120 = 0,83.
- VPN = 1000 / 1022 = 0,97.
- Prevalencia = 122 / 1144 = 0,10.
Tabla 3. Ejemplo de prueba diagnóstica realizada en población ambulante. Mostrar/ocultar
Vemos que sensibilidad y especificidad son idénticas a las anteriores, mientras que el VPP es inferior y el VPN más alto.
¿A qué se debe este cambio en los valores predictivos? Si nos fijamos, la prevalencia de enfermedad es más alta entre los pacientes del hospital (32%) que entre los del centro de salud (10%). Esto es esperable porque el paciente que acude a un hospital es más probable que esté enfermo. Así, el VPP es mayor cuando la prevalencia es más alta, mientras que el VPN es mayor cuando la prevalencia es más baja. Cuanto mayores sean las diferencias de prevalencia mayores serán los cambios en los valores predictivos o probabilidades posprueba. En este caso el cambio es pequeño, el valor predictivo positivo ha bajado de un 96% a un 83%, pero podría influir en nuestra toma de decisiones (aceptar el diagnóstico o tratar de confirmarlo con la prueba de referencia).
Esto supone una limitación. Solo podemos utilizar los valores predictivos de la prueba en poblaciones con la misma prevalencia de enfermedad que la que utilizamos para calcularlos en primer lugar. Si aplicamos la prueba diagnóstica a una población con prevalencia diferente los valores predictivos previamente calculados dejarán de ser útiles en la nueva población.
¿Y qué podemos hacer en estos casos? ¿Existe alguna forma de calcular la probabilidad posprueba en una población con distinta prevalencia a la original? La respuesta es sí, pero para eso tendremos que calcular la tercera pareja de parámetros que definen la capacidad de las pruebas diagnósticas: los cocientes de probabilidad positivo y negativo.
Cómo citar este artículo
Molina Arias M, Ochoa Sangrador C. Evaluación de la validez de las pruebas diagnósticas (II). Valores predictivos. Evid Pediatr. 2016;12:53.
Bibliografía
- Molina Arias M, Ochoa Sangrador C. Evaluación de la validez de las pruebas diagnósticas (I). Sensibilidad. Especificidad. Evid Pediatr.2016;12:34.
- Dermirdjian G, Berlín V, Rowensztein H. Pediatría basada en la evidencia. Estudios de diagnóstico (1.ª parte). Arch Argent Pediatr. 2009;107:527-35.
- Pauker SG, Kassirer JP. The threshold approach to clinical decision making. N Engl J Med. 1980;302:1109-17.
- Sensibilidad y especificidad. En: Argimón JM, Jiménez J (eds.). Métodos de investigación clínica y epidemiológica. 3.ª edición. Madrid: Elsevier; 2004. p. 335-40.
Envío de comentarios a los autores