Toma de decisiones clínicas basadas en pruebas científicas
EVIDENCIAS EN PEDIATRÍA

Diciembre 2019. Volumen 15. Número 4
| Calcupedev. Herramienta epidemiológica para clínicos
Valoración: 0 (0 Votos)Autores: Ortega Páez E, Ochoa Sangrador C, Molina Arias M.
 Suscripción gratuita al boletín de novedades
Suscripción gratuita al boletín de novedades
Reciba periódicamente por correo electrónico los últimos artículos publicados
Suscribirse |
Autores:
Correspondencia:
En la literatura médica es frecuente observar que los resultados de las investigaciones no se ofrecen de manera satisfactoria para los clínicos y se echan de menos las medidas de asociación o de impacto para poder valorar con rigor metodológico y poder aplicar los resultados a la práctica clínica habitual. Calcupedev (http://www.aepap.org/calculadora-estudios-pbe)* es una herramienta para cálculo epidemiológico que intenta suplir esta carencia en los resultados. Esta herramienta nace para asesorar a todos los clínicos y personal perteneciente al campo de la salud en su toma de decisiones en su práctica habitual.
Calcupedev está dividida en 11 hojas de cálculo independientes entre sí, que intentan abarcar los diseños epidemiológicos más frecuentes. Está pensada para estudios simples, cuando se conozcan los datos de todos los participantes (tablas de contingencia), y para estudios multivariantes cuando conozcamos solo los datos agregados o parciales de los diseños. Los resultados de cada hoja se muestran en tres grupos. En primer lugar, las pruebas de significación que evalúa la asociación estadísticamente significativa de los grupos de estudio en las tablas tetracóricas. En segundo lugar, las medidas de riesgo o asociación que valoran la magnitud de asociación entre las variables de estudio y por último las medidas de impacto, que valoran el posible impacto potencial en la población que pudiera tener la eliminación del factor de riesgo en cuestión sobre el desarrollo de la enfermedad. En general, la calculadora muestra como máximo seis decimales; si los cálculos excedieran a estos seis decimales se muestra el valor 0.
Hoja de casos clínicos 1
En la tabla tetracórica se introduce el número de participantes del ensayo clínico (EC), según presenten o no el resultado de interés y pertenezcan al grupo experimental o control. La tabla devuelve los resultados en tres apartados: pruebas de significación, medidas de riesgo y medidas de impacto.
- La prueba de significación valora la existencia de asociación de forma significativa entre los dos grupos mediante la prueba de χ2 o la prueba exacta de Fisher, en el caso de muestras pequeñas.
- Las medidas de riesgo incluyen el riesgo absoluto en los grupos de estudio, la reducción absoluta de riesgo (RAR), reducción relativa de riesgo (RRR), el riesgo relativo (RR) y la odds ratio (OR), como medida de la magnitud de la asociación entre ambos grupos. Los intervalos de confianza al 95% (IC 95) están realizados para las proporciones con aproximación de la binomial a una distribución normal de los datos. Para el RR se ha considerado la transformación logarítmica para el cálculo del error estándar (EE) mediante aproximación a la distribución normal (método de Katz). Para la OR, igualmente, realizando la transformación logarítmica y aproximando a la distribución normal según el método de Wolf que, aunque en muestras pequeñas puede magnificar el verdadero valor, es el más utilizado y recomendado.
- Dentro de las medidas de impacto se calcula el número necesario para tratar (NNT), (interpretado como número de pacientes que deberían recibir el tratamiento experimental para evitar un evento adicional. En el caso de resultado negativo, el número necesario para dañar (NND) con aproximación al número entero superior. El intervalo de confianza del NNT no se puede calcular directamente ya que no sigue una distribución normal, por lo que el método más sencillo y habitual es sustituir los límites inferior y superior por el inverso de la RAR, mediante aproximación de la binomial a una distribución normal con el método de Wald. Esto tiene el inconveniente de que para muestras pequeñas puede dar valores sobrestimados. Se ha incluido el cálculo de la probabilidad del fallo de tratamiento. Obsérvese que, si el tratamiento es eficaz y el resultado de interés es un beneficio, el NNT calculado es negativo, interpretándose como el número de pacientes que deberían recibir el tratamiento experimental para producir un evento adicional.
- En aplicabilidad clínica se calculan los NNT individualizados según el riesgo basal de nuestro paciente en particular en porcentajes o en tantos por uno, y corregido por la duración del tiempo de un estudio previo que tengamos, siempre y cuando la duración del mismo sea menor del tiempo del estudio a valorar.
Hoja de ensayos clínicos 2
Está diseñada para cuando conozcamos los datos agregados.
- En la primera tabla, “NNT a partir de los riesgos absolutos de los grupos de estudio”, la introducción de los riesgos en ambos grupos devuelve las medidas de asociación y de impacto. Para conocer los intervalos de confianza del 95% (IC 95) del NNT es necesario introducir previamente los IC 95 del RR.
- Las demás tablas son aproximaciones al RR, NNT u OR, dependiendo de los parámetros de los que dispongamos información.
- La última tabla presenta la aplicabilidad clínica mediante el cálculo del NNT conociendo el riesgo basal de nuestro paciente y corregido por el tiempo de estudio de un estudio previo que dispongamos, que debe ser menor que el tiempo de duración del estudio que estamos valorando.
Hoja de cohortes 1
En la tabla tetracórica se introducen el número de participantes según presenten o no el resultado del estudio (enfermedad) y el número de participantes según estén o no expuestos al factor de estudio. En primer lugar, calcula la probabilidad de exposición para los sujetos expuestos y no expuestos y la prevalencia de la enfermedad en el estudio. Posteriormente, la tabla devuelve los resultados en tres apartados agrupados en pruebas de significación, medidas de riesgo y medidas de impacto.
- La prueba de significación valora la existencia de asociación de forma significativa entre los dos grupos mediante la prueba de χ2 o la prueba de Mantel bilateral, como aproximación a la distribución normal, válida solo en muestras grandes.
- Medidas de riesgo. Nos ofrece los riesgos absolutos en el grupo expuesto y no expuesto, la reducción absoluta de riesgo (RAR), RR, RRR, y OR. Los IC 95 para las proporciones el RR y OR se han realizado de la misma forma que en la hoja de EC por aproximación de la distribución binomial a la normal, con la misma consideración para muestras pequeñas.
- Medidas de impacto. Se muestran los resultados según el valor del RR sea a favor del grupo expuesto (RR>1) o a favor del grupo no expuesto, protector (RR <1). Las medidas de impacto absolutas (riesgo atribuible en los expuestos [RAE] y riesgo atribuible poblacional [RAP]) y relativas (fracción atribuible en los expuestos [FAE] y fracción atribuible poblacional [FAP]). La FAP, por defecto, está calculada a partir de la prevalencia de la enfermedad del estudio, pero es posible la aproximación a partir de la proporción de casos expuestos (Pce) de un estudio previo conocido (FAP a partir de Pce). En el caso de que el factor de estudio sea protector, se calculan las proporciones prevenibles en los expuestos (PPE) y las proporciones prevenibles poblacionales (PPP). Los IC 95 se ha realizado mediante aproximación a la distribución de la binomial a la normal para diferencias de proporciones en caso de RAE, sustituyendo los limites superior e inferior del RR para la FAE y PPE, por el cálculo del EE de FAP y PPP mediante el logaritmo natural del complementario de la FAP [EE = ln (1 - FAP)] y sustituyendo los limites superior e inferior de la FAP para el RAP.
-
Números de impacto. Son los análogos del NNT para los estudios de cohortes. Se calculan por el inverso de las medidas de impacto correspondientes según el resultado del RR sea a favor de la exposición (RR >1) o en contra (RR <1). Los valores se han redondeado al número entero superior.
- Número de impacto poblacional (NIP). Es el equivalente al inverso de la RAP, aunque también es posible calcularlo por aproximación de los casos expuestos (NIP a partir de Pce).
- Número de impacto en los expuestos (NIE). El equivalente al NNT y corresponde al inverso del RAE. En el caso de factor protector se calcula el número impacto en los expuestos para prevenir (NIEP) como inverso del RAR.
- Número de impacto en los casos (NIC). Es el inverso de la FAP.
- Número de impacto en los casos expuestos (NICE): el inverso de la FAE. Los IC 95 están calculados invirtiendo los IC95 de las medidas de impacto donde proceden, el inferior por el superior y viceversa.
Hoja de cohortes 2
Diseñada para cuando conozcamos los datos agregados del riesgo absoluto de los grupos expuesto, no expuesto, la Pce o en la población general (Pep), RAR, prevalencia de la enfermedad y RR, con los IC 95 para poder calcular los IC 95 de las medidas y números de impacto. También es posible introducir el número total de expuestos y no expuestos para poder calcular los IC 95, las medidas y número de impacto que dependan de ellos, realizadas del mismo modo que en la hoja de cohortes 1. Los resultados de las distintas medidas están aproximadas a los valores que se han introducido. En el caso de que no se conozcan algunos de los parámetros a introducir, la calculadora no muestra ningún resultado. Los valores de los números de impacto están aproximados al valor entero superior.
Las cuatro últimas tablas muestran aproximaciones en estudios multivariantes:
- Aproximación a RR desde OR ajustada. Cuando los resultados se proporcionen en OR por la técnica estadística empleada (regresión logística).
- Aproximación a NNT a partir de OR ajustada. Similar al apartado anterior, en esta ocasión en vez de estimar a partir del riesgo basal, se hace por la proporción de casos en no expuestos (Pcne). En el caso de ser protector se calcula el NND.
- Aproximación a NIE (a favor del factor de exposición) o NIEP (factor exposición protector), de manera similar al anterior.
- PAP (proporción atribuible poblacional) en presencia de confusión y a partir del RR. Cuando el resultado se estima mediante OR ajustada (regresión logística) y se quiere expresar los datos en RR, normalmente cuando la prevalencia de la enfermedad es mayor del 10%.
Hoja de cohortes 3. Población-tiempo
Diseñada para los estudios de cohortes en los que el periodo de seguimiento es distinto en el grupo de expuestos y no expuestos y los resultados se expresan en tasas o densidad de incidencia. Se divide en tres secciones: pruebas de significación, medidas de riesgo y medidas de impacto.
- Pruebas de significación. Calcula si existe significación estadística entre ambos grupos mediante la prueba de χ2 y la de Mantel bilateral por aproximación de la binomial a la distribución normal de los datos, válida para muestras grandes.
- Medidas de riesgo. Calcula la tasa de incidencia en el grupo expuesto, no expuesto, la total de la muestra y la razón de tasas de incidencia (RTI), análogo al RR. Los IC 95 de las tasas de incidencia se han realizado teniendo en cuenta que el numerador del error estándar sigue una distribución de Poisson cuya varianza es igual a su media, asumiendo que el denominador es constante*.
- En las medidas de impacto se calculan las diferencias de tasas de incidencia (equivalente a la tasa de incidencia atribuible en los expuestos) y la diferencia de tasas poblacional (equivalente a la tasa de incidencia atribuible en la población general). Las fracciones atribuibles en los expuestos y poblacional si la RTI >1 y, en el caso de riesgo protector (RR <1), las fracciones prevenibles en los expuestos y poblacional. Los IC 95 se han realizado de la misma forma que en la hoja de cohortes 1.
Hoja de casos y controles 1
En la tabla tetracórica se introducen el número de casos y controles según presenten o no exposición. En primer lugar, observamos la proporción de controles y casos según su exposición. Los resultados se muestran en tres grupos: pruebas de significación, medidas de riesgo y medidas de impacto.
- Pruebas de significación. Valoran la presencia de significación estadística de la asociación entre los grupos de estudio mediante la prueba de χ2 o la de Mantel bilateral, en caso de aproximación a la distribución normal para muestras grandes.
- Medidas de riesgo. Nos muestra la odds en los grupos expuesto y no expuesto y la OR. Para los IC 95 de la OR se ha empleado el método de Wolf.
-
Las medidas de impacto se muestran según la OR sea a favor del factor de riesgo (OR >1) o en contra (OR <1). Las medidas absolutas (RAE, RAP) y las relativas (FAP y FAE). En el caso de FAP, como en el diseño de estudios de casos y controles no es posible conocer la incidencia de la enfermedad, se puede realizar la aproximación a partir de cuatro parámetros:
- Proporción de casos expuestos (Pce), la más habitual. En caso de que la enfermedad sea poco frecuente y los casos sean representativos de la población general. Los IC 95 están realizados sustituyendo los IC 95 superior e inferior de la OR.
- Proporción de expuestos en la población general (Pe), en caso de conocerla a partir de un estudio previo. Se puede sustituir por la proporción de controles expuestos (Pcte) en el estudio si la prevalencia de la enfermedad es pequeña y los controles son representativos de la población de origen. Los IC 95 se han realizado según método de máxima verosimilitud.
- Incidencia de riesgo de la enfermedad en la población general (en caso de que se conozca por estudios previos). Se ha realizado a partir de la fórmula de Withmore.
- Los números de impacto están calculados como la inversa de las medidas de impacto correspondientes a partir de los parámetros estimados vistos en el apartado anterior, aproximados al número entero superior. Al final hay una tabla de aproximación a NIE en los estudios multivariantes a partir de la OR.
Hoja de casos y controles 2
Diseñada para cuando conozcamos los resultados agregados de incidencia de riesgo en la población general, proporción de expuestos en el estudio (Pce), proporción de controles expuestos (Pcte) y la proporción de expuestos en la población general (Pe) y la OR con sus IC 95. Se calculan las medidas de impacto y números de impacto de la misma forma que en el caso de la Hoja de casos controles 1, salvo que el IC 95 de la FAP se realiza a partir de los IC 95 del RR.
Hoja de pruebas diagnósticas 1.
En la tabla tetrácorica se introducen los sujetos que han dado positivo y negativo en la prueba diagnóstica a estudiar y los que han presentado positivo y negativo en la prueba de referencia.
- En la primera parte se calculan la sensibilidad, especificidad, prevalencia de la enfermedad en el estudio, valores predictivos positivo y negativo, proporción de falsos positivos y negativos, exactitud diagnóstica de la prueba (índice de Youden), proporción de sujetos clasificados correctamente y los clasificados incorrectamente y los cocientes de probabilidad positivo y negativo. Todo con sus IC 95.
- En el apartado de cálculos bayesianos, a partir de la probabilidad preprueba (prevalencia de la enfermedad calculada en el estudio) se muestra la odds posprueba, la probabilidad posprueba y la OR diagnóstica. Los números necesarios a diagnosticar (NND), los análogos al NNT en las pruebas diagnósticas, que si son negativos irían en contra de la prueba diagnóstica. El número necesario para diagnosticar mal (NNDM) que es posible aproximarlo por el coste de los falsos positivos y negativos de la prueba diagnóstica (NNDMc). Todo ello con los IC 95, en este caso no han sido redondeados al entero inmediato superior, para facilitar su comprensión.
- En aplicabilidad clínica es posible introducir la probabilidad preprueba o prevalencia de la enfermedad a criterio del usuario y calcula los valores predictivos positivo, negativo, probabilidad posprueba positiva y negativa y el NND y NNDM. Todo ello con los IC 95.
Hoja de pruebas diagnósticas 2
Conociendo la sensibilidad y especificidad, se calculan el porcentaje de verdaderos positivos, verdaderos negativos, falsos positivos, falsos negativos, valor predictivo positivo, valor predictivo negativo y los cocientes de probabilidad positivo y negativo. Si queremos conocer los IC 95, hay que introducir los IC 95 de la sensibilidad y especificidad previamente. Podemos realizar cálculos bayesianos si conocemos la prevalencia de la enfermedad, obteniendo: las odds preprueba y postprueba, las probabilidades postprueba positiva y negativa, odds ratio diagnóstica, NND y NNMD; si introducimos el coste de falsos positivos (c0) y falsos negativos (c1) obtendremos el número necesario para mal diagnosticar corregido (NNMDc).
Estudios transversales
En la tabla tetracórica se introducen el número de enfermos y sanos según estén expuestos o no al factor de estudio. Los resultados se muestran en tres grupos: pruebas de significación, medidas de riesgo y medidas de impacto.
- Pruebas de significación. Valoran la presencia de significación estadística de la asociación entre los grupos de estudio mediante la prueba de χ2 y corrección de continuidad cuando al menos el valor de una frecuencia esperada sea menor de 5.
- Medidas de riesgo. Nos ofrece la prevalencia de enfermedad en los expuestos y no expuestos, prevalencia de exposición en los expuestos y no expuestos, la prevalencia total de enfermos, la razón de prevalencias (RP) el análogo a la OR y la razón de odds de prevalencias. Para los intervalos de confianza de las prevalencias se ha usado la aproximación de los IC 95 para una proporción y para la razón de prevalencias una fórmula análoga a la de Wolf para la OR.
- Medida de impacto. Se muestra la diferencia de prevalencias, análogo al riesgo atribuible en los estudios de cohortes. El IC 95 se ha calculado por la aproximación a la distribución normal de la binomial para diferencias de proporciones.
- Para la realización de un diseño transversal o bien para la valoración crítica de artículos científicos es frecuente utilizar el cálculo del tamaño de muestral para estimar una proporción. Introduciendo en la tabla el nivel de confianza requerido, la prevalencia de la enfermedad de estudio, la precisión con la que queremos los resultados y el porcentaje de pérdidas esperadas, nos calcula el tamaño muestral bruto o corregido por las pérdidas.
- En la última tabla se muestra la aproximación a RP a partir de la OR. Es aplicable para estimaciones de OR mediante modelos multivariantes (regresión logística). Para prevalencias <20% los valores de OR y RP son muy similares, pero para prevalencias >20% la OR sobrestima el efecto, es aconsejable calcular la RP aproximada. Se muestran dos formas: la aproximación de RP a partir de OR y la aproximación a partir del coeficiente beta, el error estándar del modelo de regresión logística y la prevalencia en no expuestos.
Estudios ecológicos
Para el análisis de los estudios ecológicos analíticos, es frecuente utilizar métodos de regresión con la tasa de mortalidad o de enfermedad como variable dependiente y la prevalencia de exposición a la enfermedad como independiente.
- Modelo aditivo. En el caso de variables cuantitativas que se ajusten a un modelo de regresión lineal simple. Conociendo los valores de los coeficientes de regresión b0 (constante del modelo), b1 (coeficiente de la variable independiente) y la prevalencia de exposición. La tabla calcula la tasa de enfermedad para la prevalencia considerada previamente, la tasa de enfermedad en los expuestos (considerando hipotéticamente que toda la población está expuesta), la tasa de enfermedad en los no expuestos (considerando hipotéticamente que toda la población no está expuesta), la diferencia de tasas, la razón de tasas y las fracciones atribuibles. Estas últimas, ajustadas a la prevalencia de enfermedad que se ha introducido previamente.
- Modelo multiplicativo. Cuando utilizamos modelos log-lineales, ajustando la regresión lineal al logaritmo natural (ln) de la tasa de enfermedad o mortalidad. La tabla realiza los mismos cálculos que en el caso del modelo aditivo. Se puede hacer también mediante regresión de Poisson cuando se modelan tasas de incidencia.
- Otros modelos. En el caso de estudios ecológicos simples en los que no se han utilizado modelos de regresión, y conozcamos solo la tasa de enfermedad en los expuestos, no expuestos y la prevalencia de la enfermedad. Se calculan las mismas medidas de impacto vistas anteriormente, la fracción atribuible en los expuestos y la fracción atribuible poblacional.
Otros usos del número necesario a tratar
En esta hoja se presentan las conversiones de los parámetros más utilizados en epidemiología a NNT.
-
Aproximación de NNT en estudios supervivencia. Se muestran dos tablas según se haya utilizado el modelo de riesgos proporcionales o el de Kaplan-Meier:
- A partir de modelo de riesgos proporcionales (regresión de Cox). Introduciendo la hazard ratio (HR) y la probabilidad de supervivencia en el grupo no tratado en el tiempo (SNT) mediante la fórmula 1/(SNTHR-SN). Esta probabilidad no es posible obtenerla directamente del modelo de Cox, pero puede estimarse desde el modelo de Kaplan-Meier o sustituirse por la supervivencia en un tiempo determinado al final del grupo no tratado (1 - probabilidad del evento en el grupo control). Para los IC 95 se han sustituido el límite superior por el inferior y el inferior por el superior de la HR.
- A partir del modelo de Kaplan-Meier. Debemos conocer la tasa de supervivencia en el grupo de tratamiento (ST) y en el grupo control (SC) para un tiempo determinado (t). El NNT se calcula mediante el inverso del RRA (1/ST-SC). El IC95 de RRA se calcula a partir del Error estándar del $$\ RRA = \sqrt{EE (ST)^2 + EE S(C)^2},$$ donde EE es el error estándar de los grupos de supervivencia. El IC 95 del NNT se obtiene, sustituyendo los límites inferior por el superior y el superior por el inferior del RRA.
-
Aproximación a NNT en variables continuas. Válido cuando se ofrecen los resultados en pruebas de significación y estamos interesados en dar el resultado en una medida común en los metanálisis y que esa medida sea el NNT.
- Aproximación a NNT desde el valor de t de Student. Se debe conocer el valor t bilateral, el tamaño muestral de ambos grupos de estudio (N1, N2), el tamaño muestral total. A partir de ahí, calcula la desviación media estandarizada como medida de efecto (DME) y por el método de Kraemer y Kupfer el NNT. Si introducimos la tasa de eventos del grupo control nos ofrece el NNT corregido mediante el método de Furukawa.
- Aproximación a NNT desde χ2. Requiere la tasa de eventos del grupo control, el valor de la χ2, el tamaño muestral total (N). Calcula el coeficiente de correlación (r), la DME y el NNT (método de Furukawa).
- Aproximación a NNT desde el coeficiente de correlación. Introduciendo la tasa de eventos del grupo control, el valor del coeficiente de correlación (r) y el tamaño muestral total, nos ofrece el NNT (método de Furukawa).
-
Aproximación NNT en variables cuantitativas. Introduciendo el tamaño muestral del grupo experimental, del grupo control, las desviaciones estándar de los grupos control y experimental y las medias del grupo control y experimental nos devuelve:
- Tamaño muestral total.
- La desviación estándar combinada de ambos grupos
- La diferencia de medias estandarizadas (DME). Medida de magnitud del efecto interpretada como porcentajes de desviaciones estándar.
- La estimación insesgada de la DME.
- Probabilidad del éxito del grupo experimental.
- Probabilidad del fallo del tratamiento.
- NNT (método de Kraemer y Kupfer). Válido si el resultado en el grupo experimental es exitoso y si el resultado es mejor que una selección aleatoria de sujetos del grupo no tratado.
-
Posteriormente se muestran tablas cuando solo tenemos conocimiento de los parámetros de forma parcial.
- Si conocemos la tasa de eventos del grupo control, calcula el NNT ajustado (método de Furukawa).
- Si conocemos la DME obtenemos la OR, la probabilidad de éxito del grupo experimental y de fallo del tratamiento con el NNT (método de Kramer y Kupfer).
- Si conocemos la Desviación estándar combinada, las medias del grupo experimental y control, obtenemos la DME, la probabilidad de éxito del grupo experimental y de fallo del tratamiento con el NNT (método de Kramer y Kupfer).
- Conociendo la DME y la tasa de eventos del grupo control obtenemos el NNT (método de Furukawa).
- Cálculo de NNT en estudios de metanálisis. Se muestran cuatro tablas en las que, introduciendo el RR, OR, diferencias de riesgos y la desviación media estandarizada con el riesgo basal o el riesgo del grupo control, siempre y cuando sea representativo de la muestra, nos devuelve el NNT.
-
Aproximación de número necesario para vacunar.
- Introduciendo la tasa de incidencia anual de la enfermedad, la efectividad de la vacuna (equivalente a la reducción relativa de riesgo) y la tasa de incidencia en no vacunados bruta nos calcula el NNV (número necesario para vacunar), calculado como 1 / tasa incidencia × efectividad de la vacuna.
- La introducción de la tasa de incidencia en no vacunados corregida por el tiempo de estudio y la tasa de incidencia en no vacunados nos ofrece la reducción absoluta de riesgo, riesgo relativo, reducción relativa de riesgo, eficacia de la vacuna y el NNT (a partir de tasas de incidencia) que según algunos autores se puede asimilar al NNV.
-
Cálculo del número necesario para cribar. En los programas de salud, es frecuente que nos preguntemos el número de sujetos que debemos realizar una prueba diagnóstica para diagnosticar una enfermedad o para disminuir la mortalidad, conocido como Número necesario para cribar (NNC).
- Introduciendo el número de afectados en el grupo control, el número de afectados en el grupo de intervención y el tamaño muestral se calcula la reducción absoluta de riesgo (RAR) y el NNC bruto (1/RAR).
- En la segunda parte de la tabla se introducen las tasas de afectados en el grupo de estudio, control y el porcentaje de participación en el estudio y nos devuelve la tasa de afectados en el grupo de intervención en ausencia de cribado, la tasa de participación ajustada por selección y el NNC ajustado a la tasa de participación y selección.
Ejemplo de funcionamiento
Para ilustrar el funcionamiento de la calculadora, sirva de ejemplo el cálculo de las medidas de impacto realizadas por los revisores en el AVC publicado en este número: Molina Arias M, Pérez-Moneo Agapito B. Riesgo de fractura e inhibidores de bomba de protones: otra razón para un uso adecuado. Evid Pediatr. 2019;15:45*.
El trabajo comentado tiene como objetivo explorar la relación entre el uso de tratamiento antisecretor (AST) de ácido en el primer año de vida, y el riesgo de fractura ósea en la infancia. El diseño es un estudio de cohortes retrospectivo. La población de estudio se compone de niños entre uno y cinco años que han tomado AST en el primer año de vida y como población control niños de uno a cinco años que no han tomado AST. Como medición de resultado se identificaron las fracturas sufridas por ambas cohortes en el primer año de vida y cuatro posteriores mediante un modelo de riesgos proporcionales (regresión de Cox) ajustando por variables de confusión. Los autores del trabajo ofrecen los resultados en HR o cocientes de riesgos instantáneos: “se observó un incremento de riesgo entre los 1 y 5 años en los niños que recibieron tratamiento supresor durante el primer año, con una HR de 1,23 (IC 95: 1,14 a 1,31) para los tratados con IBP y de 1,31 (IC 95: 1,25 a 1,37) para los tratados con IBP y anti-H2”.
El diseño es un estudio de cohortes retrospectivo persona-tiempo. Basándonos en los datos poblacionales podemos acceder al número de personas que presentan fractura entre los que toman AST (13941) y los que no lo toman (no AST) (110473) y el número de personas-tiempo a riesgo 580875 (grupo AST) y 5260609 (grupo no AST). En la calculadora, vamos a la hoja de Cohortes 3 personas tiempo para elegir la hoja de cálculo adecuada (figura 1) e introducimos los datos en la tabla tetrácorica y obtenemos la proporción de expuestos (10%) y no expuestos (90%) en la población (figura 2). A partir de aquí la calculadora nos devuelve los resultados en tres apartados, pruebas de significación, medidas de riesgo y medidas de impacto.
Figura 1. Elección del diseño la hoja de cálculo “Estudios de cohortes 3”. Mostrar/ocultar

Figura 2. Introducción de los datos en la tabla tetracórica. Mostrar/ocultar
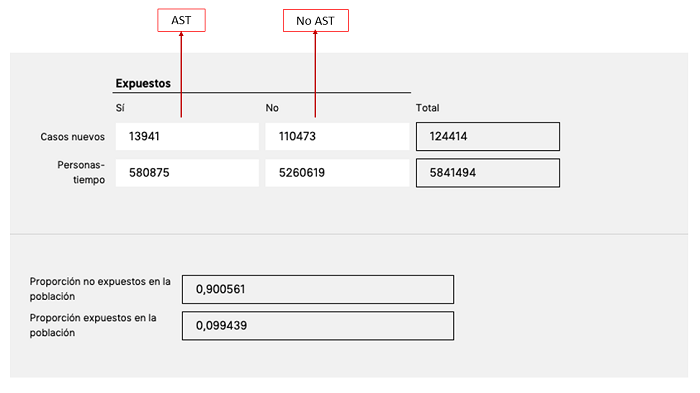
Figura 3. Pruebas de significación. Mostrar/ocultar
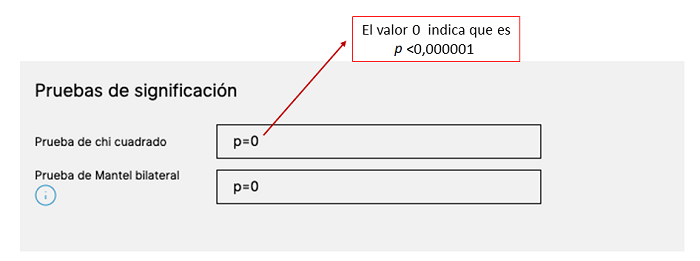
- Pruebas de significación. Nos sugiere que existe una asociación estadística entre el tratamiento con AST durante el primer año de vida y las fracturas en los 5 años siguientes, con una probabilidad de equivocarnos muy pequeña en las dos pruebas, χ2, y Mantel (p <0,000001)* (figura 3).
Figura 4. Medidas de riesgo. Mostrar/ocultar
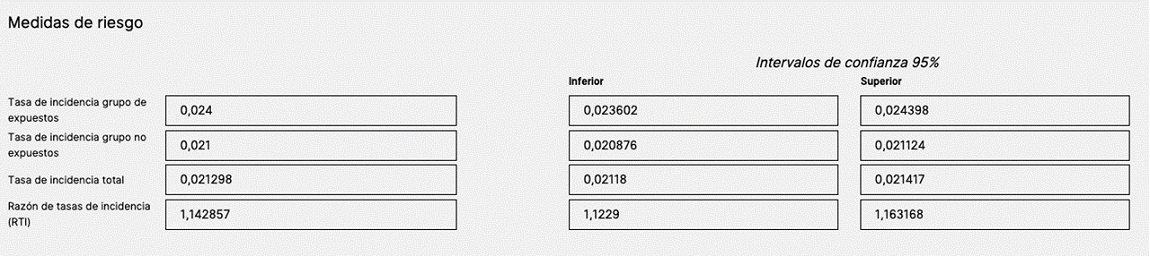
- Medidas de riesgo. Tenemos la tasa de incidencia en los expuestos (toma AST) 24/1000 persona año (IC 95: 20,08/1000 a 21,12/1000) y la tasa de incidencia en los no expuestos (no AST) 24/1000 (IC 95: 23,6/1000 a 24,3/1000). La tasa de incidencia total (TIT: 21,29/1000; IC 95: 21,18 a 21,41/1000) y la razón de tasa de incidencia: 1,14, análogo al RR, que nos dice que el riesgo de presentar fractura en los primeros cinco años en los que reciben tratamiento con AST durante el primer año de vida frente a los que no lo toman es del 14% (IC 95: 1,12 a 1,16) (figura 4).
-
Medidas de impacto (figura 5).
Figura 5. Medidas de impacto. Mostrar/ocultar
- En primer lugar, tenemos las diferencias de tasa de incidencia (equivalente a la tasa de incidencia atribuible en los expuestos) 3/1000; interpretada como que el tratamiento con AST produce por término medio 3 fracturas por cada 1000 personas año (IC 95: 2,5/1000 a 3,4/1000). Posteriormente se presenta la diferencia de tasas de incidencia poblacional (equivalente a la tasa de incidencia atribuible en la población general): 0,29/1000, interpretado como que el 0,29 de cada 1000 fracturas en niños durante los primeros cinco años a nivel poblacional se debería al tratamiento con AST (IC 95: 0,25/1000 a 0,34/1000).
- Como el RTI sobrepasa la unidad (1,14), la calculadora nos devuelve los resultados en las casillas con RT >1. La Fracción atribuible en los expuestos: 12,49%, interpretado como que el tratamiento con AST durante el primer año de vida es responsable del 12,5% (IC 95: 10,94% a 14,02%) de las fracturas en los que toman AST. La fracción atribuible poblacional: 1,4%, interpretado como que el tratamiento con AST durante el primer año de vida es responsable del 1,4% de las fracturas en los niños de hasta cinco años (IC 95: 1,2 a 1,6).

Figura 6. Elección del diseño la hoja de cálculo Otros usos del NNT. Mostrar/ocultar

Figura 7. Cálculo del NNT a partir de modelos de riesgos proporcionales. Mostrar/ocultar
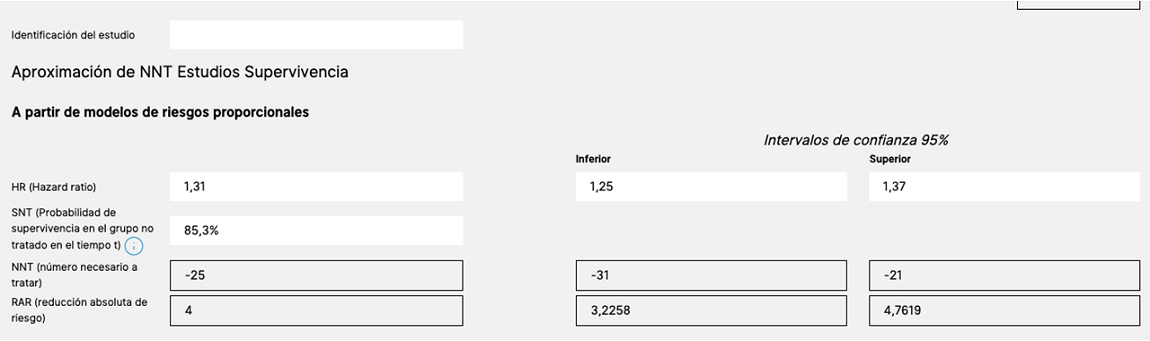
- Hasta aquí lo que podemos calcular con los datos poblacionales mediante el diseño de estudios de población-tiempo, pero a los autores de la revisión les interesaba conocer las medidas de impacto (el número necesario a tratar) calculado a partir del modelo ajustado de riesgos proporcionales, que el articulo original no proporciona. Para ello, vamos a la calculadora a la última hoja: “Otros usos del NNT” (figura 6). En primer lugar, tenemos que calcular la probabilidad de supervivencia en el grupo no tratado en el tiempo t (SNT). En el original no es posible calcularlo directamente desde el modelo de riesgos proporcionales, para ello calculamos la supervivencia en el grupo control (no AST). Calculamos el riesgo de fractura en el grupo control dividiendo por el número de niños el grupo control (110473 / 754345 = 0,146), tomando el complementario tenemos el riesgo de no fractura o supervivencia del grupo control (1 - 0,146 = 0,853). Ahora nos vamos a la primera tabla de hoja de Otros usos de NNT y elegimos la primera tabla, Aproximación NNT a estudios de supervivencia a partir de modelos de riesgos proporcionales, e introducimos los datos de la HR y sus IC 95, en los tratados con AST combinado (HR; 1,31; IC 95: 1,25 a 1,37) y la SNT = 85,3% (figura 7). Comprobamos que el NNT resultante es negativo NND: -25 (IC 95: -21 a -31), interpretándose como el número de personas que deben recibir AST para producir una fractura, por lo tanto, el resultado se ofrece en valores absolutos, NNT: 25 (IC 95: 21 a 31), interpretado que por término medio por cada 25 niños tratados con AST uno de ellos tendría una fractura adicional. El lector igualmente puede comprobar que introduciendo los datos del riesgo de los tratados solo con IBP HR de 1,23 (IC 95: 1,14 a 1,31) obtiene un NNT de 33 (IC 95: 25 a 54).
Bibliografía
- Altman DG, Andersen PK. Calculating the number needed to treat for trials where the outcome is time to an event. BMJ. 1999;319:1492-5.
- Altman DG. Confidence intervals for the number needed to treat. BMJ. 1998;317:1309-12.
- Argimón JM, Jiménez J. Métodos de investigación clínica y epidemiológica. 4.ª edición. Elsevier; 2013.
- Austin PC. Absolute risk reductions and numbers needed to treat can be obtained from adjusted survival models for time-to-event outcomes. J Clin Epidemiol. 2010;63:46-55.
- Ballester F, Tenías Burillo JM. Estudios ecológicos. Quaderns 20. Escola Valenciana d’Estudis per a la Salut; 2003.
- Bender R, Krompa M, Kiefera C, Sturtza S. Absolute risks rather than incidence rates should be used to estimate the number needed to treat from time-to-event data. J Clin Epidemiol. 2013;66:1038-44.
- Bender R, Kuss O, Hildebrandt M, Gehrmann U. Estimating adjusted NNT measures in logistic regression analysis. Stat Med. 2007;26: 5586e95.
- Bender R. Blettner M. Calculating the “number needed to be exposed” with adjustment for confounding variables in epidemiological studies. J Clin Epidemiol. 2002;55:525-30.
- Bender R. Number needed to treat (NNT). En: Encyclopedia of Biostatistics. Vol. 6. 2.ª edición. Chichester: John Wiley & Sons; 2005. p. 3752-61.
- Bjerre LM, LeLorier J. Expressing the magnitude of adverse effects in case-control studies: “the number of patients needed to be treated for one additional patient to be harmed”. BMJ. 2000:320:503-6.
- Bolumar Montrull F. Estudios de casos y controles. Barcelona: Signo; 2001.
- Borenstein M, Hedges LV, Higgins JPT, Rothstein HR. Converting among effect sizes. En: Introduction to Meta-Analysis. Chichester: Wiley; 2009.
- Breslow NE, Day NE. Statistical methods in cancer research: volume 1-the analysis of case-control studies. Lyons: Intemational Agency for Research on Cancer, 1980.
- Da Costa BR, Rutjes AW, Johnston BC, Reichenbach S, Nüesch E, Tonia T, et al. Methods to convert continuous outcomes into odds ratios of treatment response and numbers needed to treat: meta-epidemiological study. Int J Epidemiol. 2012;41:1445-59.
- Delgado Rodríguez M, Llorca Díaz J, Domenech Massons JM. Estudios transversales, ecológicos e híbridos. 4.ª edición. Barcelona: Signo; 2010.
- Delgado Rodríguez M. Estudios de cohortes. Barcelona: Signo; 2001.
- Ebrahim S. The use of numbers needed to treat derived from systematic reviews and meta-analysis Caveats and pitfalls. Eval Health Prof. 2001;24:152-64.
- Furukawa TA, Leucht S. How to obtain NNT from Cohen’s d: comparison of two methods. PLoS One. 2011;96:e19070.
- Gehrmanna U, Ksussb O, Wellmannc J, Bender R. Logistic regression was preferred to estimate risk differences and numbers needed to be exposed adjusted for covariates. J Clin Epidemiol. 2010;63:223e1231.
- Gerke O, Werner V. Number allowed to diagnose. Epidemiology. 2014;25:158-9.
- Gómez Acebo I, Diersen-Sotos T, Llorca J. Número necesario de tratamientos: interpretación y estimación en análisis multivariables y con datos censurados. Med Clin (Barc). 2014;142:451-6.
- Habibzadeh F Yadollahie M. Number needed to misdiagnose. A measure of diagnostic test effectiveness. Epidemiology. 2013;24:170.
- Heller RF, Dobson AJ, Attia J, Page J. Impact numbers: measures of risk factor impact on the whole population from case-control and cohort studies. J Epidemiol Community Health. 2002;56:606-10.
- Hildebrandt M, Bender R, Gehrmann U, Blettner M. Calculating confidence intervals for impact numbers. BMC Med Res Methodol. 2006;12:6:32.
- Katz D, Baptista J, Azen SP, Pike MC. Obtaining confidence intervals for the risk ratio in cohort studies. Biometrics. 1978;34:469-74.
- Kelly H, Attia J, Andrews R, Heller RF. The number needed to vaccinate (NNV) and population extensions of the NNV: comparison of influenza and pneumococcal vaccine programmes for people aged 65 years and over. Vaccine. 204;22:2192-2198.
- Kraemer HC, Kupfer DJ. Size of treatment effects and their importance to clinical research and practice. Biol Psychiatry. 2006; 59:990-96.
- Laaksonen M. Population attributable fraction (PAF) in epidemiologic follow-up studies. Helsinki: National institute for Health and Welfare; 2010.
- Llorca J, Fariñas-Álvareza C, Delgado-Rodríguez M. Fracción atribuible poblacional: calculo e interpretación. Gac Sanit. 2001;15:61-7.
- Morgenstern H. Ecologic studies in epidemiology: concepts, principles, and methods. Annu Rev Public Health. 1995;16:61-81.
- Morris JA, Gardner MA. Calculating confidence intervals for relative risks (odds ratios) and standardised ratios and rates. BMJ. 1988;296:1313-6.
- Nieto FJ, Peruga A. Riesgo atribuible: sus formas, usos e interpretación. Gac Sanit. 1990;18:112-7.
- Nuesch E, Tonia T, Gemperi A, Guyatt GH, Junil P. Methods to convert continuous outcomes into odds ratios of treatment response and numbers needed to treat: meta-epidemiological study. Int J Epidemiol. 2012;41:1445-59.
- Ortega Páez E, Molina Arias M. Medidas de impacto potencial en epidemiología (1). Medidas de impacto absolutas. Evid Pediatr. 2017;13:62.
- Ortega Páez E, Molina Arias M. Medidas de impacto potencial en epidemiología (2). Medidas de impacto relativas. Evid Pediatr. 2018;14:14.
- Primo J. Índices de eficacia de un tratamiento. NNT (II/II). Enfermedad Inflamatoria Intestinal al día. 2003;2:62-6.
- Rembold CM. Number needed to screen: development of a statistic for disease screening. BMJ. 1998;317:307-12.
- Richardson A. Screening and the number needed to treat. J Med Screen. 2001;8:125-7.
- Rothman KJ, Greenland S, Lash TL. Modern epidemiology. 3.ª edición. Lippincott Williams & Wilkins; 2008.
- Sackett DL, Straus SE, Richardson WS, Rosenberg W, Haynes RB. Medicina basada en la evidencia: cómo practicar y enseñar la MBE. 2.ª edición. Madrid: Harcourt; 2001.
- Schiaffino A, Rodríguez M, Pasarín MI, Regidor MI, Borrell C, Fernández E. ¿Odds ratio o razón de proporciones? Su utilización en estudios transversales. Gac Sanit. 2003;17:70-4.
- Zocchetti C, Consonni D, Bertazzi P. Relationship between prevalence rate ratios and odds ratios in cross-sectional studies. Int J Epidemiol. 1997;6:220-3.
Cómo citar este artículo
Ortega Páez E, Ochoa Sangrador C, Molina Arias M. Calcupedev. Herramienta epidemiológica para clínicos. Evid Pediatr. 2019;15:53.
Envío de comentarios a los autores